
Harness DevOps Platform: Intelligent CI/CD at Scale
In today’s fast-paced digital economy, downtime isn’t just an inconvenience — it’s a measurable business risk. Even seconds of service disruption can cost millions, erode customer confidence, and expose compliance liabilities. That’s why resilience — the ability of systems to maintain expected service levels despite failures, stress, or unexpected conditions — has moved from a “nice to have” to a critical enterprise capability.
Recognizing this shift, Harness has introduced Resilience Testing, a new module within its broader AI and DevOps platform designed to help organizations proactively measure, validate, and optimize the robustness of their mission-critical applications.
Unlike traditional testing approaches that focus on correctness under normal conditions, resilience testing simulates real-world chaos — system failures, peak traffic surges, or disaster scenarios — to reveal weak points before they hit production. The result is not only higher uptime but also greater confidence in continuous delivery workflows.
What Is Resilience Testing?
At its core, resilience testing enables teams to assess how systems respond under stress or failure — and to measure that response quantitatively. Harness’ implementation brings together three core pillars:
🔹 Chaos Testing
Chaos tests inject controlled faults into applications or infrastructure to mimic realistic outages. This could be random instance terminations, increased latency, service crashes, or resource exhaustion. Chaos experiments help teams uncover hidden dependencies and anticipate how services degrade or recover.
🔹 Load Testing
Load tests simulate high traffic conditions to measure performance ceilings and bottlenecks. Instead of waiting for real traffic spikes, teams can generate controlled load that mimics anticipated peak demand, enabling capacity planning and performance tuning.
🔹 Disaster Recovery (DR) Testing
DR tests verify that backup and failover procedures actually work, not just theoretically exist. By simulating a disaster (data center failure, regional outage, etc.), organizations can confirm that recovery goals and incident response playbooks are effective.
Together, these pillars provide a multidimensional view of system health — from everyday stability to infrastructure resilience under pressure.
Key Features That Make Harness Resilience Testing Enterprise-Ready
Harness Resilience Testing isn’t a standalone chaos tool — it’s integrated into a modern DevOps ecosystem with features tailored for enterprise adoption.
🌐 Seamless DevOps Integration
Resilience Testing integrates directly with CI/CD pipelines and monitoring tools. Teams can embed resilience checks into deployment workflows so that every build and release includes reliability validation — not just functional testing.
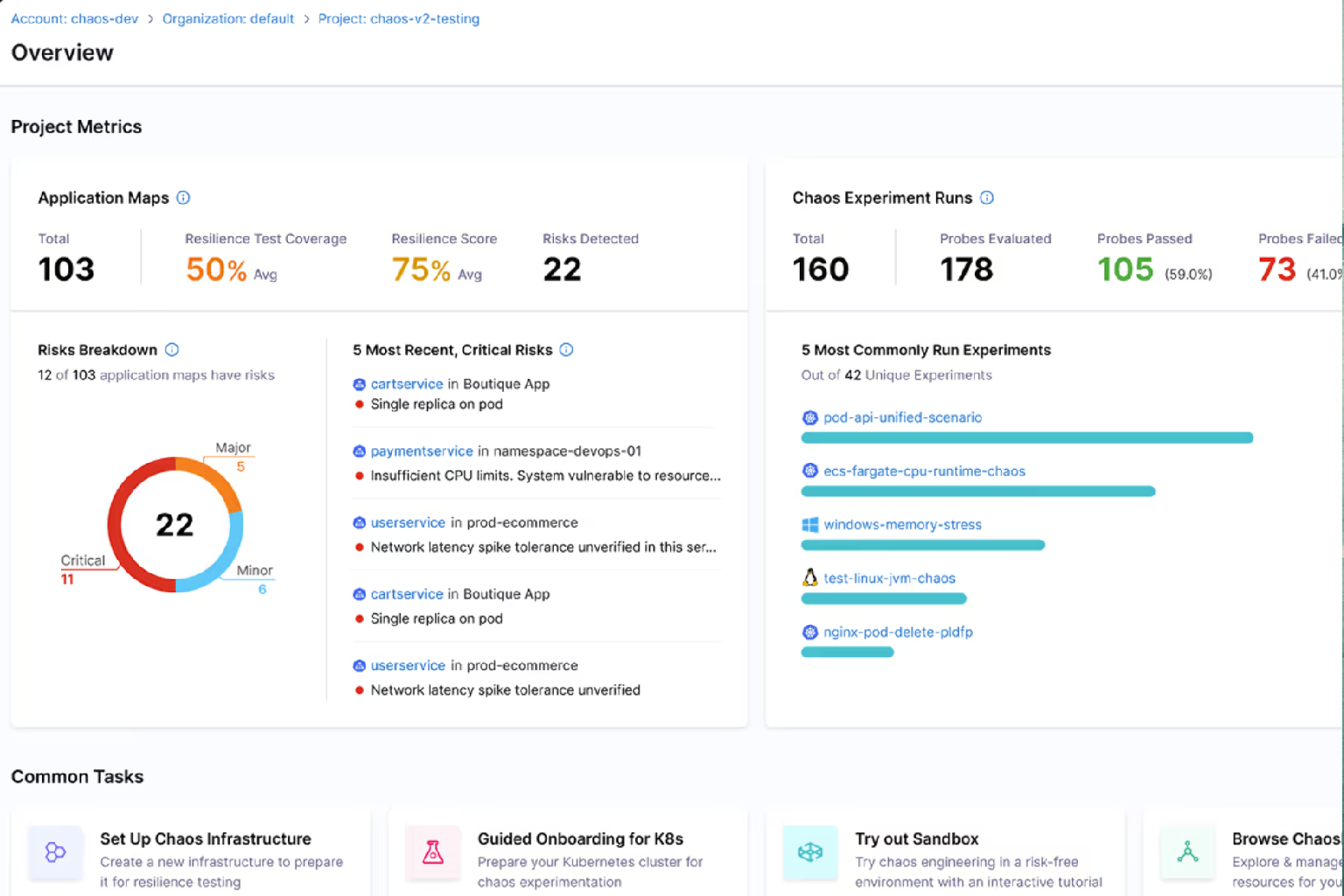
🔍 Resilience Probes
Instead of requiring manual observation, resilience probes automatically monitor system behavior during tests. These probes track whether the system maintains expected conditions and feed data back into resilience scoring and analytics.
🎯 AI-Powered Insights
Harness includes an AI Reliability Agent that offers intelligent recommendations — from crafting impactful experiments to optimizing existing ones and diagnosing failures. This capability helps teams reduce guesswork and surface high-impact weaknesses.
📊 Resilience Score & Coverage Metrics
Harness generates a resilience score — a quantitative metric from 0 to 100 — that summarizes how well a system withstands injected faults. Teams can track resilience posture over time, prioritize improvements, and set quantifiable targets.
🛡️ ChaosGuard & Governance
Enterprise governance is built in. Role-based access control (RBAC), audit logs, and scheduling policies ensure that only permitted experiments run on production systems, and only within safe time windows.
🧠 GameDay Portal for SREs
Site Reliability Engineering (SRE) teams can orchestrate controlled GameDays — simulated incident scenarios — with a curated portal that encourages cross-team readiness and collaboration.
☁️ Flexible Deployment
Harness supports both SaaS and on-premise deployments, ensuring that organizational policies, security requirements, and compliance needs are respected. Even the free tier includes core resilience capabilities for experimentation.
Why Resilience Testing Matters Now
🚨 The Cost of Unplanned Outages
Modern applications are distributed — microservices, containers, cloud APIs, and multi-region deployments are the norm. This complexity increases the attack surface for failures. Traditional test environments can’t replicate real failure conditions, leaving teams blindsided when a real issue occurs.
Enter resilience testing: a proactive way to surface vulnerabilities before customers do.
Chaos engineering has evolved from a niche discipline pioneered by companies like Netflix (e.g., Chaos Monkey) into an essential practice for teams that demand operational confidence.
⚙️ Better Development Workflows
By embedding resilience testing into CI/CD pipelines:
-
Developers think about reliability as part of development
-
QA teams validate functional and non-functional behavior together
-
SREs gain visibility into failure modes before production
This approach shifts testing “left” — upstream in the lifecycle — reducing costly rollback cycles and improving deployment frequency.
📈 Business Continuity Intelligence
Resilience scores and coverage metrics give business leaders quantifiable indicators of readiness. Instead of vague statements like “our systems are stable,” teams can point to data that tracks improvements over time, supports change approvals, and justifies resilience investments.
Real-World Use Cases
Here are practical examples where resilience testing delivers value:
✔ High Availability Systems
For services that must meet strict uptime SLAs, resilience testing verifies that redundancy, failover, and recovery mechanisms actually work under load.
✔ Microservices Architecture
In a distributed environment, dependent services often fail in unexpected ways. Controlled chaos helps isolate fault impacts before they ripple through production.
✔ Disaster Recovery Validation
Organizations with compliance requirements (like finance or healthcare) can automate DR testing instead of manual periodic drills, saving time and improving confidence.
✔ DevOps Culture & Skill Building
GameDays and chaos experiments empower teams to think collaboratively about failure — not just delivery — embedding reliability into culture.
What Makes Harness’ Approach Stand Out
Harness’ resilience testing isn’t just another chaos tool. It’s part of an AI-powered delivery platform that unifies:
-
CI/CD workflows
-
Security & compliance dashboards
-
Feature management and experimentation
-
Cost governance
-
Resilience and reliability automation
This breadth allows teams to not only test for failures but also make resilience decisions part of measurable, repeatable software delivery processes.
Challenges and Best Practices
To gain maximum value from resilience testing:
🔹 Start Small, Scale Fast
Begin with critical services and expand experiments gradually.
🔹 Automate Probes and Scoring
Rely on automated metrics rather than manual observation for faster insights.
🔹 Integrate With Existing Monitoring
Link chaos experiments to APM tools like Datadog, Prometheus, or New Relic for richer diagnostics.
🔹 Govern Experiment Execution
Use governance policies to control when and where chaos tests run — especially in production.
Conclusion: Resilience as a First-Class DevOps Practice
Modern DevOps is not just about rapid delivery — it’s about confident delivery. Confidence comes from knowing how systems perform under both normal and abnormal conditions.
Harness Resilience Testing offers a unified platform where chaos engineering, load simulation, disaster recovery validation, and intelligent insights work together. For teams seeking to harden their software delivery pipelines, reduce downtime, and build trust in automated workflows, resilience testing isn’t optional — it’s essential.
For more information please visit Harness.













{kind=link}