
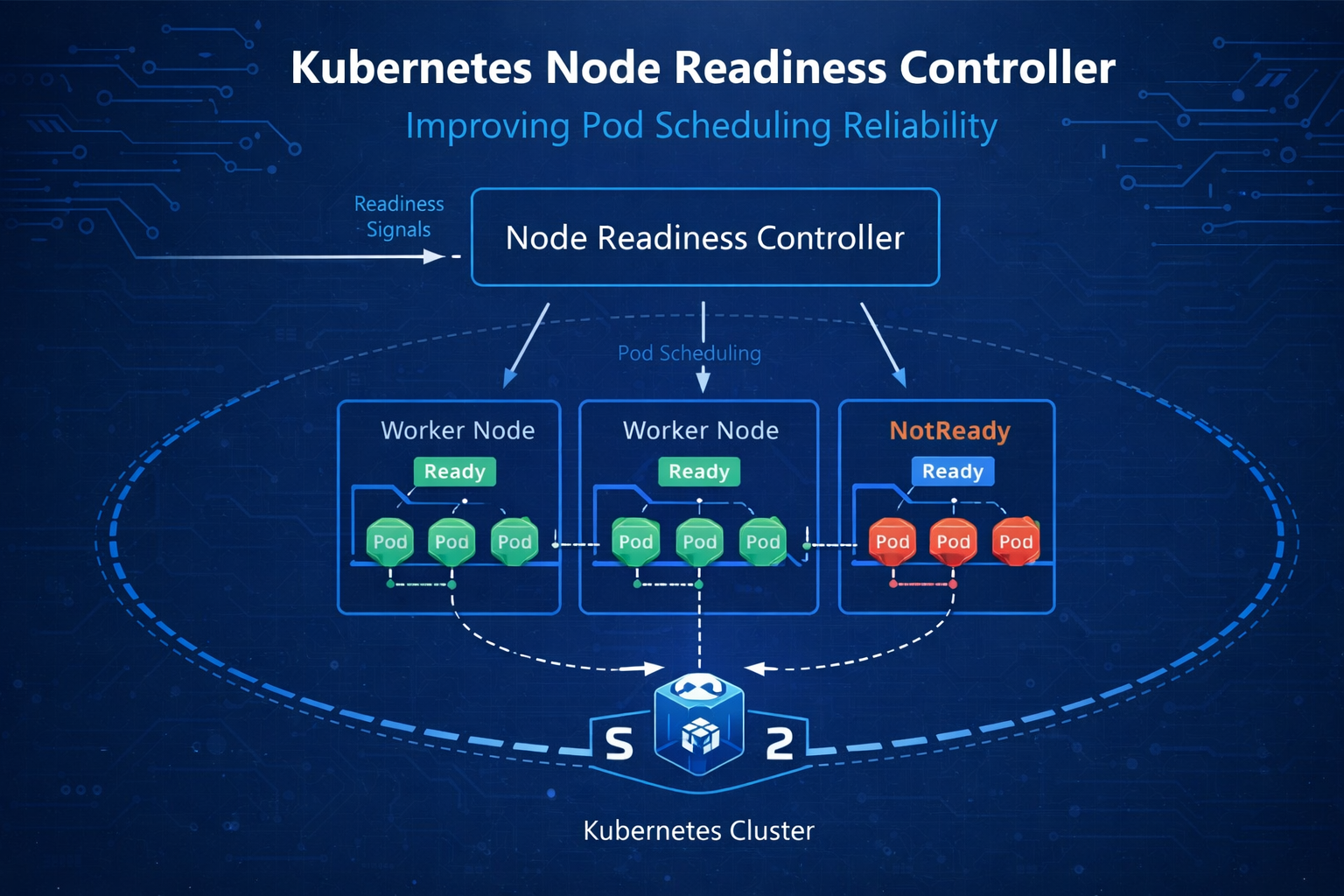
Kubernetes continues to evolve in ways that directly address real-world operational pain points. One of the latest improvements — the introduction of a Node Readiness Controller — focuses on a core reliability issue: ensuring pods are only scheduled onto nodes that are genuinely ready to handle them.
For teams running production workloads at scale, this is not a minor tweak. It represents a meaningful enhancement in how Kubernetes manages node health, scheduling decisions, and cluster stability.
Let’s break down what this new controller does, why it matters, and how it impacts day-to-day DevOps operations.
The Scheduling Problem Kubernetes Has Been Quietly Fighting
Kubernetes scheduling has always depended on node conditions. A node marked as “Ready” is eligible to receive pods. A node marked “NotReady” is avoided.
Sounds simple.
But in real-world environments, node state transitions aren’t always clean or instantaneous. Network partitions, kubelet restarts, resource pressure, or control plane delays can create gray areas where:
-
A node appears Ready but is functionally unstable
-
A node briefly disconnects and reconnects
-
The scheduler makes placement decisions based on stale readiness signals
-
Pods land on nodes that immediately degrade
When this happens, teams see:
-
Pod restarts
-
CrashLoopBackOff events
-
Failed rollouts
-
Deployment instability
-
Reduced cluster confidence
The Node Readiness Controller aims to make this entire process more deterministic and resilient.
What the Node Readiness Controller Actually Does
At a high level, the Node Readiness Controller adds an additional layer of logic around how node readiness is evaluated and enforced.
Instead of relying solely on immediate readiness conditions, Kubernetes now applies a more structured control mechanism that:
-
Continuously evaluates node health signals
-
Reconciles readiness state transitions
-
Ensures consistency before allowing scheduling
-
Prevents premature pod placement
This controller improves synchronization between kubelet state, node conditions, and scheduler behavior.
In practical terms, it reduces the chance that pods get scheduled onto nodes that are technically “Ready” but operationally unreliable.
Why This Matters for Production Workloads
If you’re running stateless demo workloads, minor scheduling inconsistencies may not hurt you.
But in enterprise environments running:
-
Stateful applications
-
Financial systems
-
Real-time APIs
-
High-availability services
-
Machine learning pipelines
-
Distributed databases
Even small instability can cascade quickly.
Consider a rolling deployment. If new pods are scheduled onto nodes that are about to fail or are partially degraded, you may see:
-
Deployment delays
-
Health check failures
-
Load balancer flapping
-
Temporary traffic loss
-
Failed progressive rollouts
The Node Readiness Controller strengthens the reliability of the entire deployment pipeline.
How It Improves Pod Scheduling Reliability
Kubernetes scheduling reliability depends on three main components:
-
Accurate node health reporting
-
Timely state reconciliation
-
Intelligent scheduling decisions
The new controller enhances the second and third layers.
1. Better Readiness Validation
Instead of allowing immediate scheduling after a node reports Ready, the controller can ensure the readiness state is stable and consistent across signals.
This prevents scheduling during transient recovery windows.
2. Improved State Reconciliation
Nodes that flap between Ready and NotReady states can create unpredictable scheduling patterns. The controller helps smooth these transitions and avoid aggressive scheduling behavior during instability.
3. Stronger Guardrails for the Scheduler
The Kubernetes scheduler is only as good as the information it receives. By improving how readiness data is validated and managed, scheduling decisions become more trustworthy.
This leads to fewer unnecessary pod evictions and fewer failed scheduling attempts.
Real-World Impact for DevOps Teams
This isn’t just a control plane refinement — it directly affects daily operations.
Here’s what changes for teams managing clusters:
More Predictable Deployments
Rollouts become more stable because pods are placed on genuinely healthy nodes.
Reduced Noise
Fewer transient failures mean fewer alerts and less troubleshooting.
Improved SLO Adherence
Service Level Objectives tied to uptime and deployment reliability benefit from fewer unexpected pod failures.
Stronger Multi-Zone Stability
In clusters spanning multiple availability zones, transient node issues can have amplified impact. More disciplined readiness enforcement strengthens zone-level resilience.
Interaction with Existing Kubernetes Mechanisms
The Node Readiness Controller doesn’t replace existing mechanisms like:
-
Taints and tolerations
-
Pod disruption budgets
-
Node affinity rules
-
Resource-based scheduling
Instead, it enhances the underlying reliability of the readiness signal itself.
Think of it as strengthening the foundation rather than adding a new scheduling feature.
Everything built on top — affinity rules, autoscaling, rolling updates — benefits from more accurate readiness evaluation.
Implications for Autoscaling and Cluster Operations
Cluster autoscalers depend heavily on node state transitions.
If nodes are added or removed rapidly, or if readiness reporting is inconsistent, autoscaling decisions can become unstable.
With improved readiness control:
-
New nodes are less likely to receive pods before being fully operational
-
Scale-down events are less likely to disrupt healthy workloads
-
Scheduling churn is reduced
For organizations running large dynamic clusters, this reduces unnecessary pod movement and resource thrashing.
Security and Stability Intersections
While the Node Readiness Controller is primarily a reliability enhancement, it also intersects indirectly with security.
Nodes in partially degraded states may:
-
Miss security policy updates
-
Fail to apply admission controls consistently
-
Experience delayed kubelet communication
By enforcing clearer readiness state transitions, the cluster avoids scheduling workloads into uncertain or degraded nodes.
That indirectly improves the overall security posture of production environments.
What DevOps Teams Should Do Now
The introduction of this controller doesn’t require panic or immediate rearchitecture. But teams should:
-
Review Kubernetes version notes carefully
-
Test readiness behavior in staging clusters
-
Observe scheduling logs during rollouts
-
Monitor changes in pod placement patterns
Understanding how readiness enforcement evolves ensures you avoid surprises during upgrades.
For teams running mission-critical systems, validation in non-production environments is especially important.
The Bigger Pattern in Kubernetes Evolution
This change reflects a broader trend in Kubernetes development:
Moving from feature velocity to operational maturity.
In the early years, Kubernetes focused heavily on adding capabilities — new APIs, new workload types, new scheduling features.
Now the focus is increasingly on:
-
Stability
-
Predictability
-
Reliability under scale
-
Operational safety
The Node Readiness Controller is a perfect example of this shift.
It doesn’t introduce a flashy new abstraction.
It strengthens the invisible mechanics that make everything else work more smoothly.
Final Thoughts
Kubernetes Introduces Node Readiness Controller to Improve Pod Scheduling Reliability is more than just a release headline. It’s a signal that the project continues to refine the reliability of its core scheduling engine.
For organizations running production-grade clusters, this means:
-
Fewer scheduling surprises
-
More consistent rollouts
-
Improved uptime
-
Stronger infrastructure confidence
In modern cloud-native environments, reliability isn’t just about scaling up — it’s about ensuring that every scheduling decision is made on trustworthy, stable information.
The Node Readiness Controller moves Kubernetes one step closer to that goal.













{kind=link}